Fisher's exact test is a
statistical significance test used in the analysis of tables
where
sample
sizes are small. It is named after its inventor,
R. A. Fisher, and is one of a class ofexact tests, so called because the significance of the deviation from a
null hypothesis can be calculated exactly, rather than relying on an approximation that becomes exact in the limit as the sample size grows to infinity, as with many statistical tests. Fisher is said to have devised the test following a comment from <Muriel Bristol, who claimed to be able to detect whether the tea or the milk was added first to her cup.
The test is useful for
categorical data that result from classifying objects in two different ways; it is used to examine the significance of the association (contingency) between the two kinds of classification. So in Fisher's original example, one criterion of classification could be whether milk or tea was put in the cup first; the other could be whether Ms Bristol thinks that the milk or tea was put in first. We want to know whether these two classifications are associated - that is, whether Ms Bristol really can tell whether milk or tea was poured in first. Most uses of the Fisher test involve, like this example, a 2 x 2 contingency table. The
p-value from the test is computed as if the margins of the table are fixed, i.e. as if, in the tea-tasting example, Ms. Bristol knows the number of cups with each treatment (milk or tea first) and will therefore provide guesses with the correct number in each category. As pointed out by Fisher, this leads under a null hypothesis of independence to a
hypergeometric distribution of the numbers in the cells of the table.
With large samples, a
chi-square test can be used in this situation. The usual rule of thumb is that the chi-square test is not suitable when the expected values in any of the cells of the table, given the margins, is below 10: the
sampling distribution of the test statistic that is calculated is only approximately equal to the theoretical chi-squared distribution, and the approximation is inadequate in these conditions (which arise when sample sizes are small, or the data are very unequally distributed among the cells of the table). In fact, for small, sparse, or unbalanced data, the exact and asymptotic
p -values can be quite different and may lead to opposite conclusions concerning the hypothesis of interest.
[4] [5] The Fisher test is, as its name states, exact, and it can therefore be used regardless of the sample characteristics. It becomes difficult to calculate with large samples or well-balanced tables, but fortunately these are exactly the conditions where the chi-square test is appropriate.
For hand calculations, the test is only feasible in the case of a 2 x 2 contingency table. However the principle of the test can be extended to the general case of an
m x
n table
[6], and some
statistical packages provide a calculation (sometimes using a
Monte Carlo method to obtain an approximation) for the more general case.
Example
For example, a sample of teenagers might be divided into male and female on the one hand, and those that are and are not currently dieting on the other. We hypothesize, perhaps, that the proportion of dieting individuals is higher among the women than among the men, and we want to test whether any difference of proportions that we observe is significant. The data might look like this:
| |
men |
women |
total |
| dieting |
1 |
9 |
10 |
| not dieting |
11 |
3 |
14 |
| totals |
12 |
12 |
24 |
These data would not be suitable for analysis by a chi-squared test, because the expected values in the table are all below 10, and in a 2 \xD7 2 contingency table, the number of degrees of freedom is always 1.
The question we ask about these data is: knowing that 10 of these 24 teenagers are dieters, and that 12 of the 24 are female, what is the probability that these 10 dieters would be so unevenly distributed between the women and the men? If we were to choose 10 of the teenagers at random, what is the probability that 9 of them would be among the 12 women, and only 1 from among the 12 men?
Before we proceed with the Fisher test, we first introduce some notation. We represent the cells by the letters
a, b, c and
d, call the totals across rows and columns
marginal totals, and represent the grand total by
n. So the table now looks like this:
| |
men |
women |
total |
| dieting |
a |
b |
a + b |
| not dieting |
c |
d |
c + d |
| totals |
a + c_ |
b + _d |
n |
Fisher showed that the
probability of obtaining any such set of values was given by the
hypergeometric distribution:


where
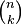
is the
binomial coefficient and the symbol ! indicates the
factorial operator.
This formula gives the exact probability of observing this particular arrangement of the data, assuming the given marginal totals, on the
null hypothesis that men and women are equally likely to be dieters. Fisher showed that we could deal only with cases where the marginal totals are the same as in the observed table. (
Barnard's test relaxes this constraint on one of the marginal totals.) In the example, there are 11 such cases. Of these only one is more extreme in the same direction as our data; it looks like this:
| |
men |
women |
total |
| dieting |
0 |
10 |
10 |
| not dieting |
12 |
2 |
14 |
| totals |
12 |
12 |
24 |
In order to calculate the significance of the observed data, i.e. the total probability of observing data as extreme or more extreme if the
null hypothesis is true, we have to calculate the values of
p for both these tables, and add them together. This gives a
one-tailed test; for a
two-tailed test we must also consider tables that are equally extreme but in the opposite direction. Unfortunately, classification of the tables according to whether or not they are 'as extreme' is problematic. An approach used by the
R programming language is to compute the p-value by summing the probabilities for all tables with probabilities less than or equal to that of the observed table. For tables with small counts, the 2-sided p-value can differ substantially from twice the 1-sided value, unlike the case with test statistics that have a symmetric sampling distribution.
As noted above, most modern
statistical packages will calculate the significance of Fisher tests, in some cases even where the chi-squared approximation would also be acceptable. The actual computations as performed by statistical software packages will as a rule differ from those described above, because numerical difficulties may result from the large values taken by the factorials. A simple, somewhat better computational approach relies on a
gamma function or log-gamma function, but methods for accurate computation of hypergeometric and binomial probabilities remains an active research area.
References
- ^ Fisher, R. A. (1922). "On the interpretation of χ2 from contingency tables, and the calculation of P". Journal of the Royal Statistical Society 85 (1): 87-94. JSTOR:2340521.
- ^ Fisher, R.A. (1954). Statistical Methods for Research Workers. Oliver and Boyd.
- ^ Agresti, Alan (1992). "A Survey of Exact Inference for Contingency Tables". Statistical Science 7 (1): 131-153.
- ^ Mehta, Cyrus R; Patel, Nitin R; Tsiatis, Anastasios A (1984), "Exact significance testing to establish treatment equivalence with ordered categorical data", Biometrics 40: 819–825, doi:10.2307/2530927
- ^ Mehta, C. R. 1995. SPSS 6.1 Exact test for Windows. Englewood Cliffs, NJ: Prentice Hall.
- ^ mathworld.wolfram.com Page giving the formula for the general form of Fisher's exact test for m x n contingency tables