| Design | Sampling | Measure of Association |
|---|---|---|
| Case-cohort | Entire cohort at baseline | risk ratio |
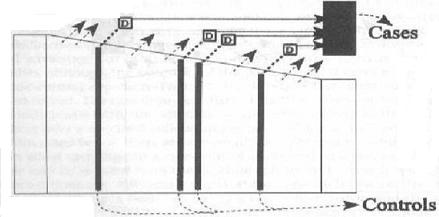
| Incidence-density | Non-cases at time of diagnosis | rate ratio |
| Prevalent Case Control | Non-cases at single point in time | odds ratio |
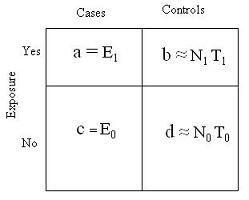
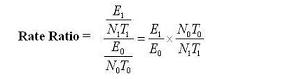 So analogous to estimating risk ratio, we need to estimate the proportion:
So analogous to estimating risk ratio, we need to estimate the proportion: