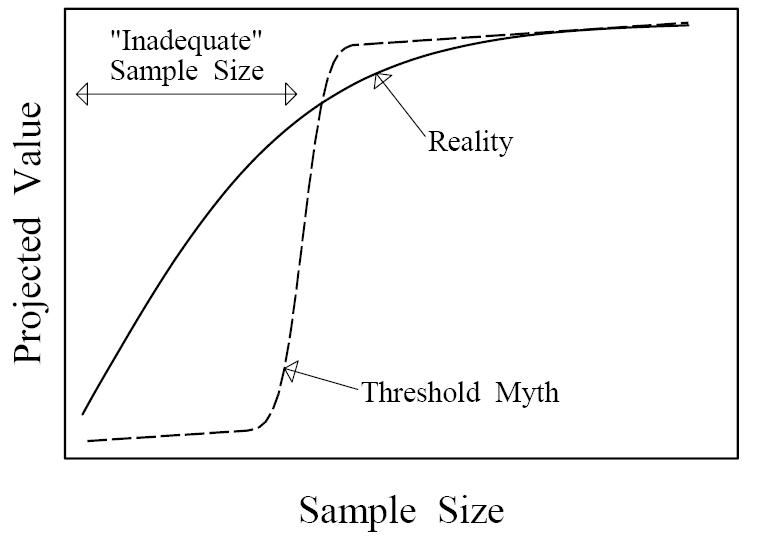
Figure 1. Qualitative depiction of how sample size influences a study's projected scientific and/or practical value. A threshold shaped relationship (dashed line) would create a meaningful distinction between adequate and inadequate sample sizes, but such a relation does not exist. The reality (solid line) is qualitatively different, exhibiting diminishing marginal returns. Under the threshold myth, cutting a sample size in half could easily change a valuable study into an inadequate one, but in reality such a cut will always preserve more than half of the projected value.